
Our lab studies cognition and perception, with a particular focus on spoken language comprehension and speech perception. We use a variety of tools to study these processes, primarily the event-related brain potential (ERP) technique, eye-tracking, behavioral experiments, and computational modeling approaches.
Some questions we are interested in include:
Our research intersects with several areas of cognitive science, including cognitive psychology, neuroscience, linguistics, and AI. A key aspect of our approach is understanding cognitive and perceptual processing as it happens, using measures that allow us to study processes that unfold over millisecond-level timescales.
Principles of
Speech Perception
Context and
Top-down Effects
Computational
Cognitive Science

Effects of
Hearing Difficulty
Human listeners are remarkably adept at understanding spoken language, despite considerable variability in the speech signal due to differences between talkers' voices, speaking rate, coarticulatory context, and other factors. How do listeners overcome this variability to successfully understand speech with so little effort?
Our work provides support for two key principles that allow listeners to solve this problem: (1) sensitivity to fine-grained acoustic detail in the speech signal, and (2) perceptual processes that are shaped by higher-level linguistic context (more on this below).
Support for the first principle comes from work demonstrating that early cortical ERP responses, such as the auditory N1, track continuous changes in the acoustic signal, independently of listeners' phonological categories. Later-occurring responses, such as the P3, also show sensitivity to within-category acoustic differences (Toscano et al., 2010, Psychological Science). Other work has demonstrated that this sensitivity persists for several seconds over multiple words (Falandays, Brown-Schmidt, & Toscano, 2020, Journal of Memory and Language).
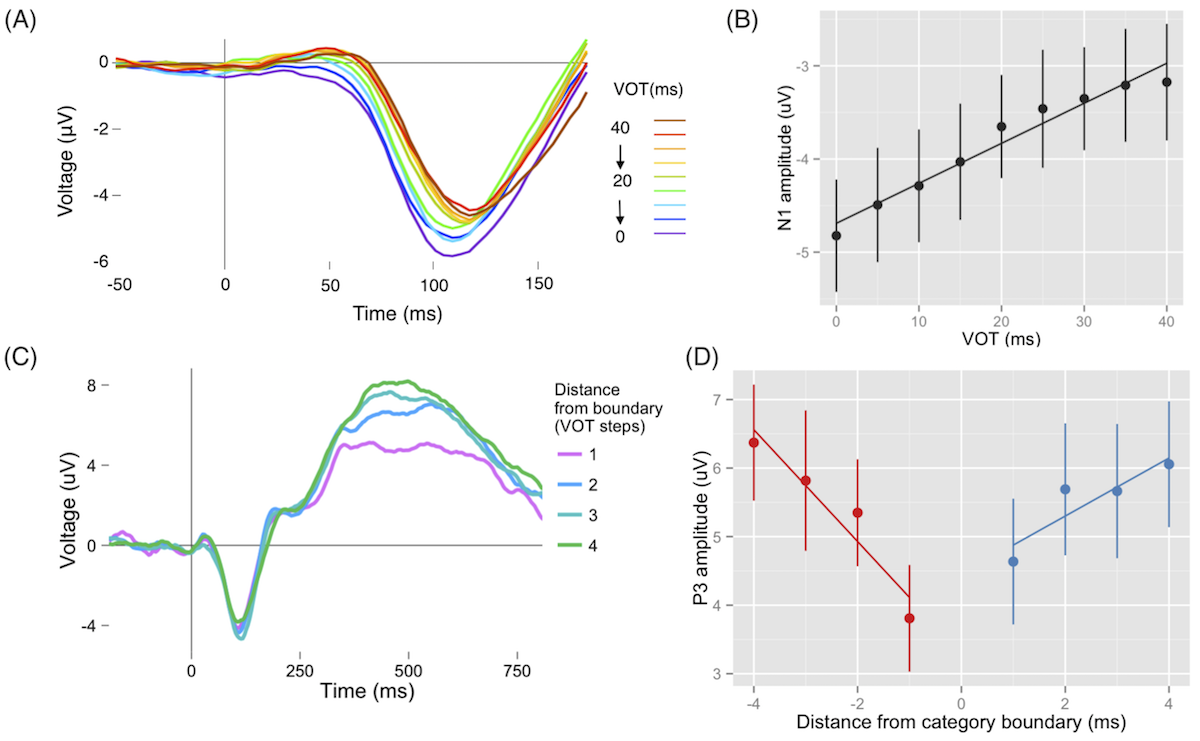
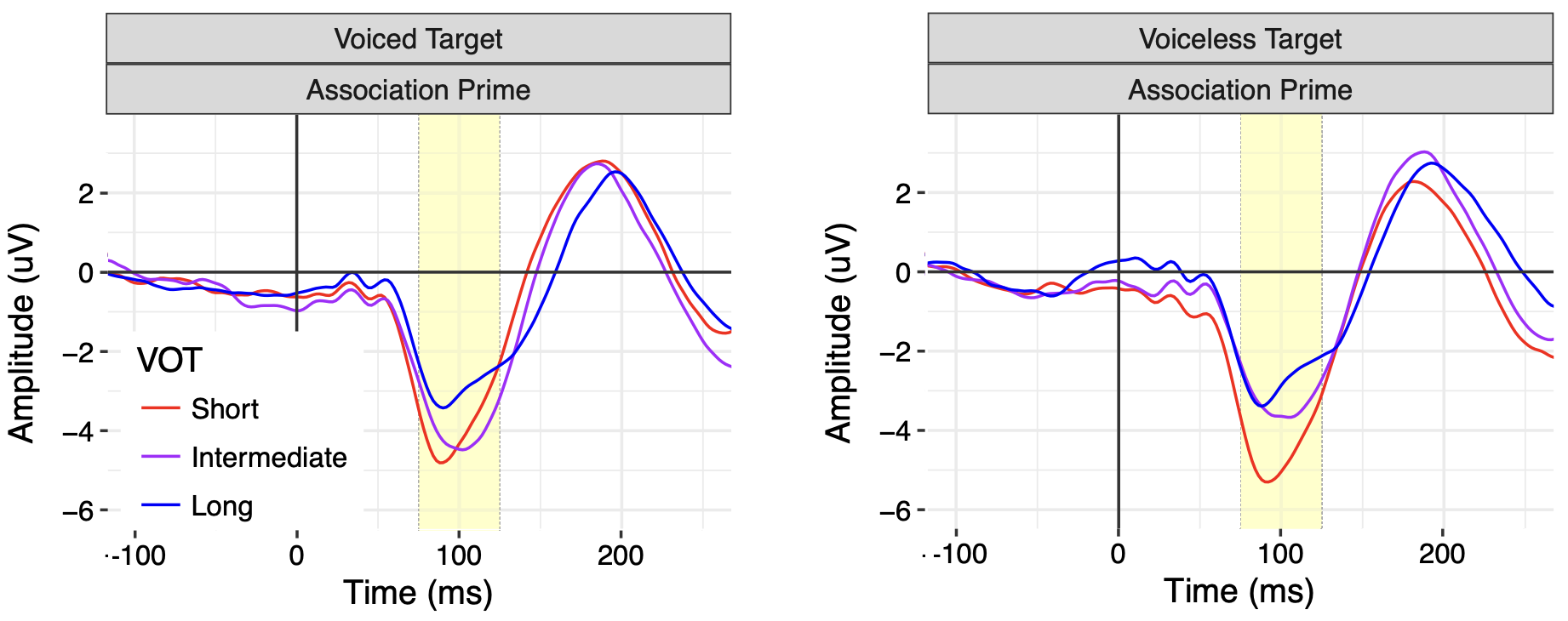
ERP data for speech sounds varying in voice onset time (VOT). (A) ERP waveforms as a function of VOT during the time range of the N1. (B) Mean N1 amplitude as a function of VOT, showing a linear effect across the VOT continuum consistent with encoding of continuous acoustic cues. (C) ERP waveforms as a function of distance from category endpoints. (D) Mean P3 amplitude as a function of distance from category endpoints. Unlike the N1, the P3 is affected by both listeners' phonological categories, and graded acoustic cues (Toscano et al., 2010).
We have studied these processes in a number of projects using both cognitive neuroscience methods (the ERP technique and fast optical imaging) and eye-tracking approaches. Together, these techniques provide a window into the millisecond-by-millisecond processes that occur during speech perception. In recent work, we have been developing and using machine learning methods to decode differences in neural data that provide more sensitive measures of the timecourse of language processing, offering new opportunities to study these processes in greater detail (Sarrett & Toscano, 2024, Psychophysiology).
More about this topic:
Early perceptual processes are also influenced by top-down expectations. For example, given a predictive linguistic context (e.g., expecting the word park to occur after the word amusement), listeners encode ambiguous speech sounds in a way that is consistent with their expectation (an ambiguous sound at the onset of b/park is encoded like a "p" in the context of the word amusement; Getz & Toscano, 2019, Psychological Science). Encoding speech sounds relative to context allows listeners to overcome variability in the speech signal, and it demonstrates a robust top-down effect on early speech perception.
The N1 response, which tracks early perceptual encoding of speech sounds, varies based on semantic expectation (Getz & Toscano, 2019).
Other types of context effects can be revealed by tracking the time-course of speech perception using the visual world eye-tracking paradigm, revealing how listeners use and integrate different types of cues. For instance, listeners adjust their use of temporal cues, such as voice onset time, baed on preceding sentential context (Toscano & McMurray, 2015), but treat other rate-dependent cues independently (Toscano & McMurray, 2012).
Overall, these results suggest that the language processing system is highly interactive, allowing listeners to integrate information across different levels of linguistic organization in real time. Ongoing work is investigating other types of context effects and the types of information that feedback to influence early speech sound encoding.
More about this topic:
Computational approaches provide a way to study how perceptual and cognitive processes can be implemented in specific models. Several projects in the lab have focused on developing and using computational models to refine and test hypotheses about speech perception, learning, and development.
GMM learning speech sound categories over development.
We use several types of models to study these processes. Gaussian mixture models can be used to study how human infants acquire speech sound categories via unsupervised learning (McMurray, Aslin, & Toscano, 2009, Developmental Science) and how they learn to weight acoustic cues based on their reliability (Toscano & McMurray, 2010, Cognitive Science), graph theoretic approaches can be used to identify which acoustic cues are most useful for speech sound categorization in a way that accounts for variability across talkers (Crinnion, Malmskog, & Toscano, 2020), and simulations with neural network models, can be used to understand the processes underlying lexical competition (Toscano, Anderson, & McMurray, 2013, Psychonomic Bulletin & Review).
These models have provided insights about the processes used by human listeners to learn speech sound categories and to understand what information in the speech signal they use to accomplish this. In our current research, we are working to combine computational models of cognitive processing with contemporary machine learning and AI approaches.
More about this topic:
Fifteen percent of American adults report experiencing hearing difficulty and over one billion young people are exposed to sound levels that put them at risk for noise-induced hearing loss. Moreover, many listeners who appear to have normal hearing still report difficulty, particularly for understanding speech in noise.
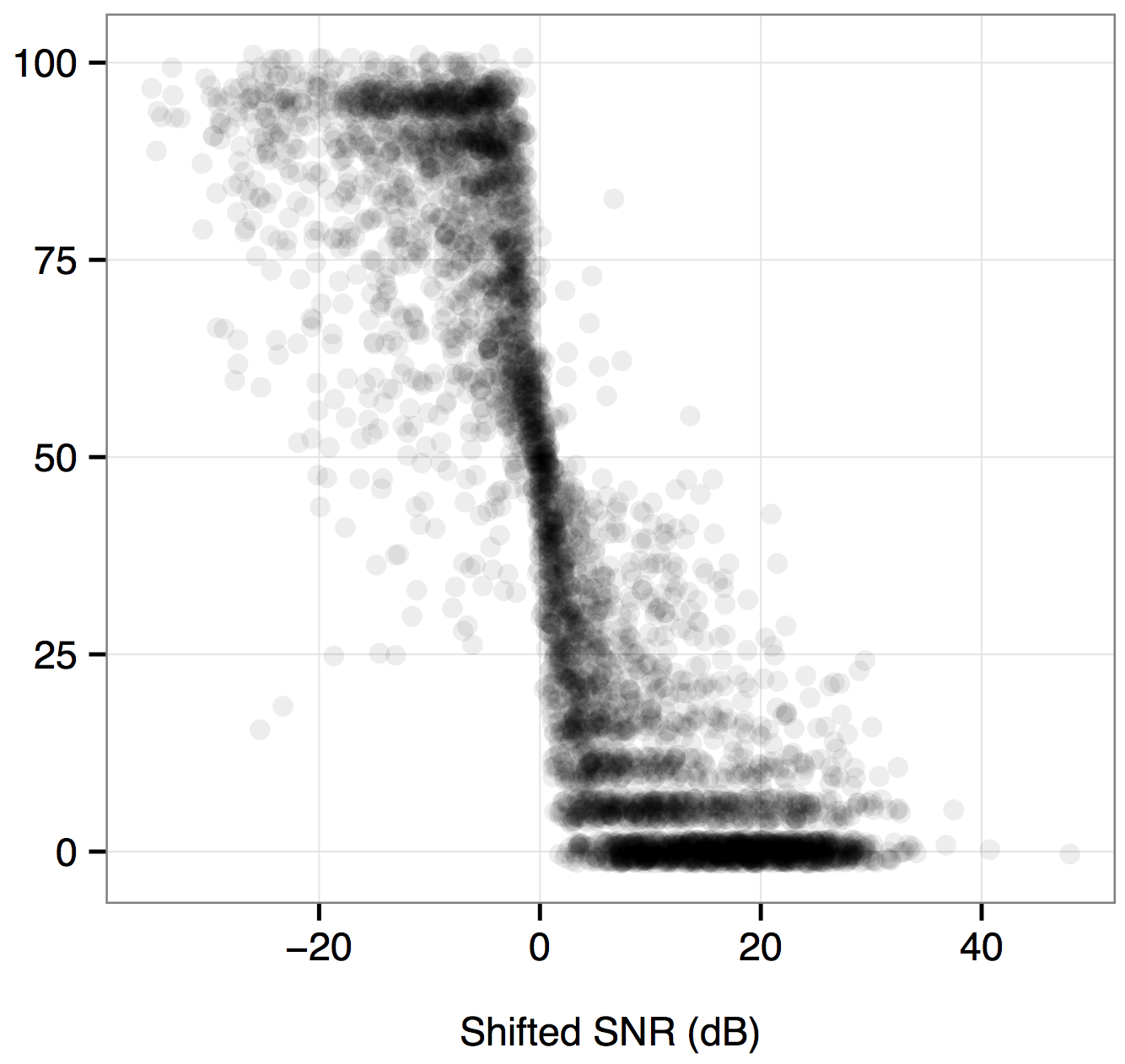
Listeners' error functions for individual speech sounds, centered at their 50% point. The figure shows that most tokens cluster together to form similar functions once token-level error thresholds are accounted for. This suggests that adjusting for token-level differences can explain the majority of errors that listeners make.
Despite a need for tests that assess the effects of hearing difficulty on speech recognition, speech-based tests have had limited success. One reason for this is that these tests typically average across different talkers and consonants. As a result, they are less sensitive to subtle differences in fine-grained acoustic cues that are important for speech perception.
Indeed, differences in the acoustic properties of specific sounds account for the majority of errors made by normal-hearing listeners (Toscano & Allen, 2014), suggesting that tests that account for token-level differences between speech sounds may be more effective in assessing the effects of hearing difficulty on speech recognition. Electrophysiological measures could provide another source of information. For example, auditory brainstem responses can be used to measure frequency encoding (Tabachnick & Toscano, 2018), providing a measure of a listener's ability to encode acoustic differences.
Other contexts can lead to challenging listening conditions as well. During the COVID-19 pandemic, listeners were confronted with the challenge of understanding speech produced with a face mask. Listeners are rather accurate at recognizing speech produced with a mask in quiet, but some masks yield better speech recognition accuracy than others in the presence of background noise (Toscano & Toscano, 2021). Moreover, listeners showed similar performance at earlier and later time points during the pandemic (Crinnion et al., 2022), suggesting that they may have adapted quickly to understanding speech produced with a mask or that there is an upper limit on accuracy, even with significant exposure to mask-produced speech and time to adapt.
More about this topic:
Powered by w3.css